kaggle平台&Notebook基础用法教程
这篇文章将介绍kaggle平台的基础使用方法和Notebook相关的操作与技巧等。不仅仅针对本次“慧炼丹心杯”,也希望能够为大家日后参加其他kaggle平台上的比赛打下一些基础。
Kaggle 是一个全球知名的数据科学和机器学习社区平台,由 Anthony Goldbloom 于 2010 年创立,2017 年被 Google 收购。它旨在为数据科学家、机器学习工程师、研究人员和爱好者提供协作、学习和竞赛的环境。
Kaggle 最著名的功能是举办各类数据科学竞赛,企业或研究机构提供真实问题和数据集,参赛者通过构建模型解决这些问题,优胜者获得奖金或工作机会。此外,Kaggle 托管了超过 50,000 个公开数据集,涵盖金融、医疗、体育、社会科学等多个领域。
注册
注册往往是新手需要跨过的第一个门槛。注册时需要使用VPN,否则会收不到谷歌的验证码。在平时使用平台的时候,往往挂着VPN也会获得更加流畅的体验。
开始
 如果你是刚刚学习机器学习的新手,kaggle有些经典的竞赛任务供你学习。其中最经典的包括 Titanic - Machine Learning from Disaster | Kaggle泰坦尼克号存活预测和Housing Prices Competition for Kaggle Learn Users | Kaggle房价预测。当你看到泰坦尼克号排行榜的时候可能会疑惑为什么大家分数都拉满了,这是因为这个比赛过于经典,测试集已经被大家找出来,或者过拟合了。
如果你是刚刚学习机器学习的新手,kaggle有些经典的竞赛任务供你学习。其中最经典的包括 Titanic - Machine Learning from Disaster | Kaggle泰坦尼克号存活预测和Housing Prices Competition for Kaggle Learn Users | Kaggle房价预测。当你看到泰坦尼克号排行榜的时候可能会疑惑为什么大家分数都拉满了,这是因为这个比赛过于经典,测试集已经被大家找出来,或者过拟合了。
Kaggle是一个十分提倡开放与共享的社区。在比赛的过程中,很多选手会在Discussion区域踊跃地讨论,也有部分选手会选择公开自己的代码,供其他选手学习与优化。泰坦尼克号比赛中,你可以参考这个Notebook:Titanic Tutorial,它包含了基本的数据探索与简单的模型构建流程。
Kaggle Notebook 使用指南
1. Notebook 核心功能
Kaggle Notebook 是基于 Jupyter Notebook 的云端编程环境,提供开箱即用的 Python/R 数据分析与建模工具。主要特点包括:
- 快速访问:在比赛或数据集页面的 Code 标签页中,点击 New Notebook 即可创建。
- 预装环境:内置主流数据科学库(如 NumPy、Pandas、Scikit-learn),无需手动配置。
- 无缝集成:可直接挂载 Kaggle 平台数据集,支持版本控制与协作编辑。
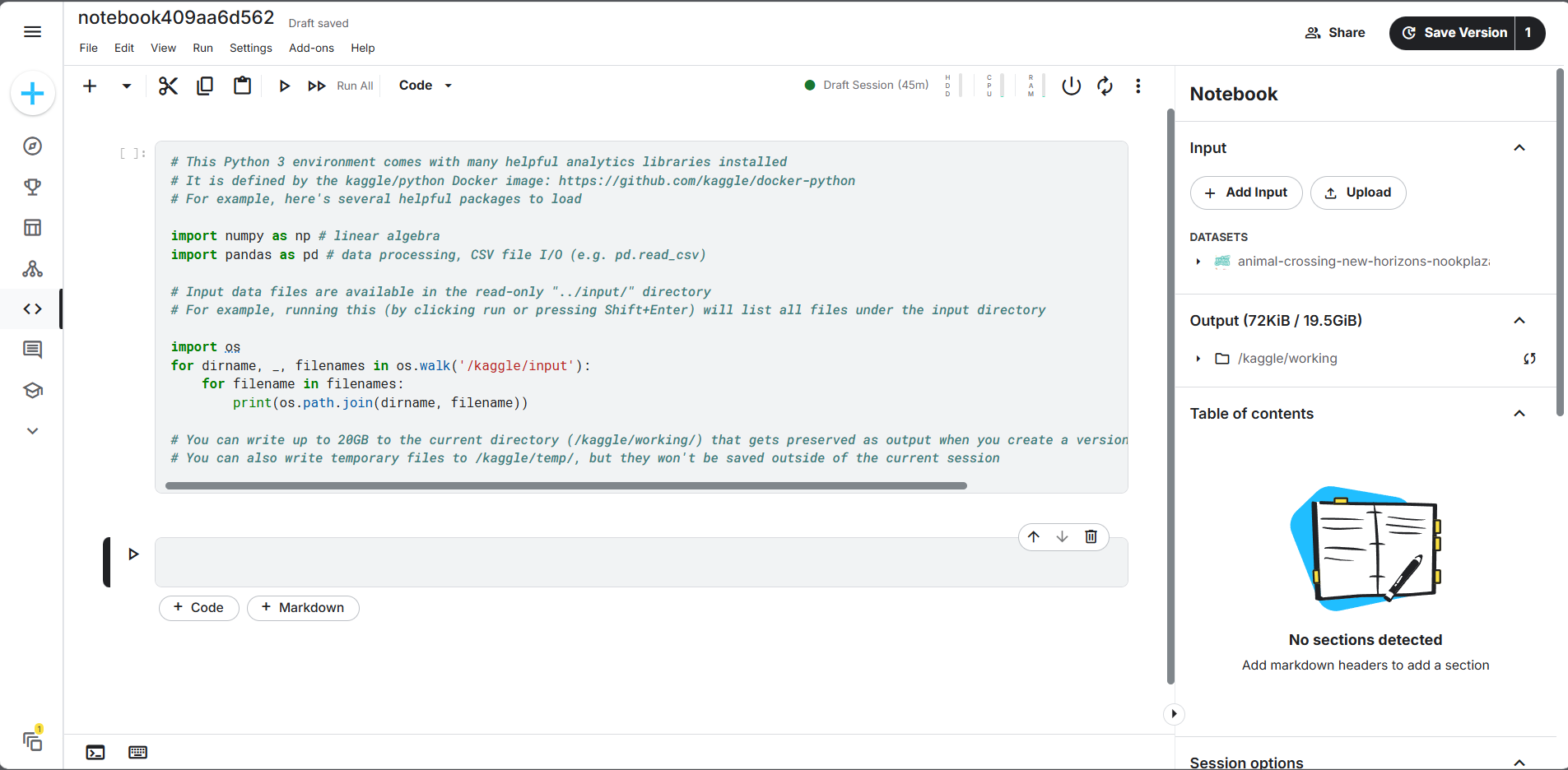
2. 计算资源与加速器
Kaggle 为免费用户提供 GPU/TPU 加速资源:
- GPU:每周 30 小时 配额(当前搭载 NVIDIA P100/T4 显卡)。
- TPU:每周 20 小时 配额。
- 适用场景:适合需要加速训练的深度学习任务。
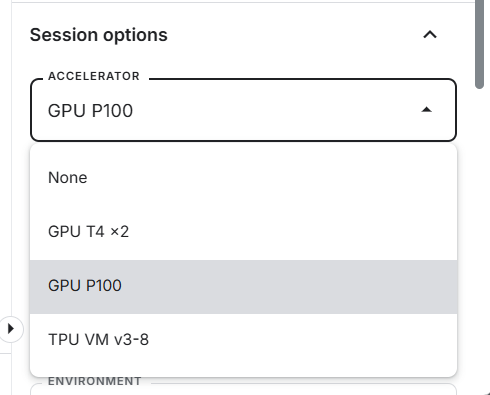
💡 若本地计算资源不足,可以白嫖 Kaggle 的免费加速器。Kaggle给的免费计算资源真的是很良心了,T4和P100都是不错的卡。
3. 文件系统结构
Kaggle Notebook 的文件系统采用 隔离目录设计,结构如下:
/kaggle
├── input # 只读目录:挂载数据集(自动关联比赛或数据集文件)
│ └── your-dataset
└── working # 可写目录:存放临时文件(Notebook 会话结束后自动清除)
└── your-current-workdir- input 目录:仅可读取,禁止修改或写入。你所加载的其他数据集将被放在这里。
- working 目录:唯一可写区域,用于存放生成的文件(如中间数据、模型权重、输出结果)
4. 调用 Linux 命令
在 Notebook 中,可通过 ! 前缀直接执行 Shell 命令,例如:
# 安装第三方库(仅在当前会话有效)
! pip install seaborn
# 查看文件系统
! ls /kaggle/input
# 更新软件包列表(需 sudo 权限)
! sudo apt update5. 数据上传与灵活使用
数据上传规则
Kaggle 允许上传 任意类型文件 至数据集(Dataset),包括:
- 模型权重(
.pth、.h5、.ckpt等) - Python 依赖包(
.whl、.tar.gz) - 自定义工具代码(
.py、.sh) - 预处理中间文件(如特征工程后的
.pkl文件) 你可以通过主页左侧的Datasets页面,再点击 New Dataset 上传你本地的任何数据。后续它们可以在Notebook中被引用。 你可以直接上传压缩包,Kaggle会自动帮你解压。
使用技巧
(1)代码模块化
为保持 Notebook 简洁,部分选手会将工具函数拆分到 /kaggle/working 目录下的自定义模块中:
# 将 utils.py 上传至 Dataset,复制到工作目录
!cp /kaggle/input/my-dataset/utils.py /kaggle/working/
# 在 Notebook 中导入
from utils import preprocess_data当然,这么做的维护成本可能会有点高。一般来说,我们还是会在Notebook中定义一长串函数。
(2)依赖管理
若需安装额外的依赖库,需要提前将 .whl 文件上传至 Dataset,通过绝对路径安装:
!pip install /kaggle/input/custom-packages/torch-1.12.0-cp37-cp37m-linux_x86_64.whl⚠️ 注意
- 上传文件需遵守 Kaggle 内容政策,禁止上传侵权或恶意文件。
/kaggle/working为临时目录,会话结束自动清空,重要文件需下载或提交到 Output。
6. 记得保存!
Kaggle Notebook保存有两种选项:
- Save & Run All (commit) : 完全跑一遍 Notebook 再保存。同时,在Code Competition中,在你提交code的时候也会被强制执行这一步,以确保你的提交能够成功。
- Quick Save: 保存Notebook的当前状态。
7. Code Competition 解析
Code competition是目前Kaggle平台公开比赛主要的比赛形式(炼丹杯不是这种比赛形式)。它的特点是不将测试集提供给选手,选手需要完全通过Notebook处理流程在线上进行推理预测。最终选手需要按照要求,生成submission.csv文件。 一般来说,这种比赛的文件结构类似这样:
文件结构规范
标准目录结构如下:
/kaggle
├── input
│ └── competition-name # 比赛数据(只读)
│ ├── train/ # 训练数据
│ │ └── data.csv
│ └── test/ # 示例测试数据(正式运行时会替换为完整版)
│ └── data.csv
└── working # 可写目录(代码输出必须在此生成)
└── submission.csv # 最终提交文件依赖解决方案
由于大部分的Code Competition禁用网络,需 预先离线化所有依赖:
- 本地准备:在与 Kaggle 环境一致的系统中打包依赖:
pip download pandas==1.3.5 -d ./packages # 下载指定版本库- 上传至 Dataset:将生成的
.whl或.tar.gz文件作为数据集上传。 - 代码中安装:
# 安装离线包
!pip install --no-index --find-links=/kaggle/input/my-packages/ pandas