图神经网络工程实践
本体论与形而上学
什么是“本体论(ontology)”?
叠甲:下面的这段有点扯淡的讨论完全是本人的一家之言,无参考文献,当我在乱说就行
可能很多人会很疑惑,我们一上来怎么在讲哲学?
在研究图结构和知识图谱时,“本体论”这一概念经常被提及。本体论源于哲学领域,但在计算机科学中已发展出特定含义。
在计算机科学和信息科学中,本体论指的是对特定领域内概念、实体及其关系的形式化表达。它定义了概念的分类体系、属性特征以及实体间的关联方式。简单来说,本体论为我们提供了一个结构化的知识框架,使计算机能够”理解”特定领域中存在的对象类型及其相互关系。^[1]
形而上学与辩证法
形而上学作为哲学的一个重要分支,研究存在的本质和基本规律,而本体论正是形而上学的核心组成部分。在传统形而上学视角下,世界被视为由相对静态、确定的实体和关系构成。这种思想在知识图谱领域表现为:
-
静态关系建模:将实体间的关系视为固定不变的事实(如”水是H₂O”、“北京是中国首都”)
-
明确的类别划分:实体被严格归类(如”药物”、“疾病”、“人物”等不同类别)
-
确定性知识表示:关系要么存在,要么不存在,缺乏不确定性和上下文相关性
然而,现实世界中的关系往往更为复杂、动态且具有上下文依赖性。以医学领域为例:“阿司匹林可治疗头痛”这一简单陈述背后,隐藏着诸多复杂因素:治疗效果可能因人而异,存在特定禁忌人群,可能产生副作用,治疗效果有时间窗口,需要特定剂量,等等。这些微妙而重要的信息无法通过简单的三元组关系(阿司匹林-治疗-头痛)完整表达。
每一个实体,都是复杂的,辩证的。几个孤立的关系,往往无法建模一个完整的、辩证的实体。 然而从辩证法的视角看,万物都是对立、统一的。本体论虽然属于形而上学的哲学体系,但从辩证法的视角看,本体论与辩证法之间亦有中矛盾而又统一的一面。当知识图谱中关系的量变产生质变,当我们积累了数百万条关系时,我们就能够突破知识表示与推理的形而上学边界。
例如,对于阿司匹林,我们可能这么建模(实际上,阿司匹林在生物医学知识图谱中的关系数量远远多于这个):
以阿司匹林为例,在复杂的知识图谱中,它可能被表征为:
- 化学属性:乙酰水杨酸,分子式C₉H₈O₄
- 药理机制:抑制前列腺素合成,抑制血小板聚集
- 适应症:疼痛(头痛、牙痛、关节痛),发热,心血管疾病预防
- 剂量关系:低剂量(75-100mg)用于心血管保护,中剂量(325-650mg)用于镇痛
- 禁忌人群:胃溃疡患者,12岁以下儿童(与瑞氏综合征相关,置信度0.8)
- 副作用:胃肠道刺激(发生率约15%),过敏反应(发生率<1%)
- 药物相互作用:与华法林同用增加出血风险(风险等级:高),与布洛芬同用降低心血管保护作用
- 时间依赖性:长期服用可能增加胃溃疡风险,但同时提高心血管保护效果
而打破这道边界的武器,就是图游走算法,以及图神经网络算法。它们不再局限于单一关系的表示,而是通过分析整体图结构的拓扑特性,捕捉实体之间的隐含联系和复杂模式。通过对海量关系数据的综合分析,这些算法可以更全面地理解实体之间的辩证关系,实现更加智能、灵活的知识表示与推理。
图神经网络历史
图神经网络出现之前
- 描述逻辑(Description Logic)
- 用于本体推理(如OWL-DL)。
- 规则引擎(Rule Engines)
- 如Drools、Jess,用于专家系统
- 随机游走(Random Walk)
- PageRank等算法用于图结构分析^[2]
- path based reasoning
- 矩阵分解
- 概率图模型(用于不确定性推理)
- …
GNN(Graph Neural Networks) 是用于处理图结构数据的深度学习模型。与传统神经网络如 CNN RNN 不同,GNN直接对图结构进行建模,能够捕捉复杂的拓扑关系
图数据
同构图
同构图是指图中所有节点和边都属于同一类型的图结构。 例子:
- 社交网络中的用户关注关系图(所有节点都是用户,所有边都是关注关系)
- 网页链接图(所有节点都是网页,所有边都是超链接)
异构图
包含多种类型的节点和边,结构复杂。
- 生物医学知识图谱
- 电商网络
- 学术网络
有向/无向?
对于有向图、无向图和混合有向、无向边的图,图神经网络可以有不同的处理方式。
图表示学习 GRL(Graph Representation Learning)
将图结构数据(节点、边、图级别)映射到低维向量空间的方法。GNN属于这种方法。很多时候,我们专注于节点的表征,即利用节点及其周围节点的拓扑结构,对节点进行表征。
这种表征的方式类似于 Bert,将一个节点映射到一个高维的向量空间。
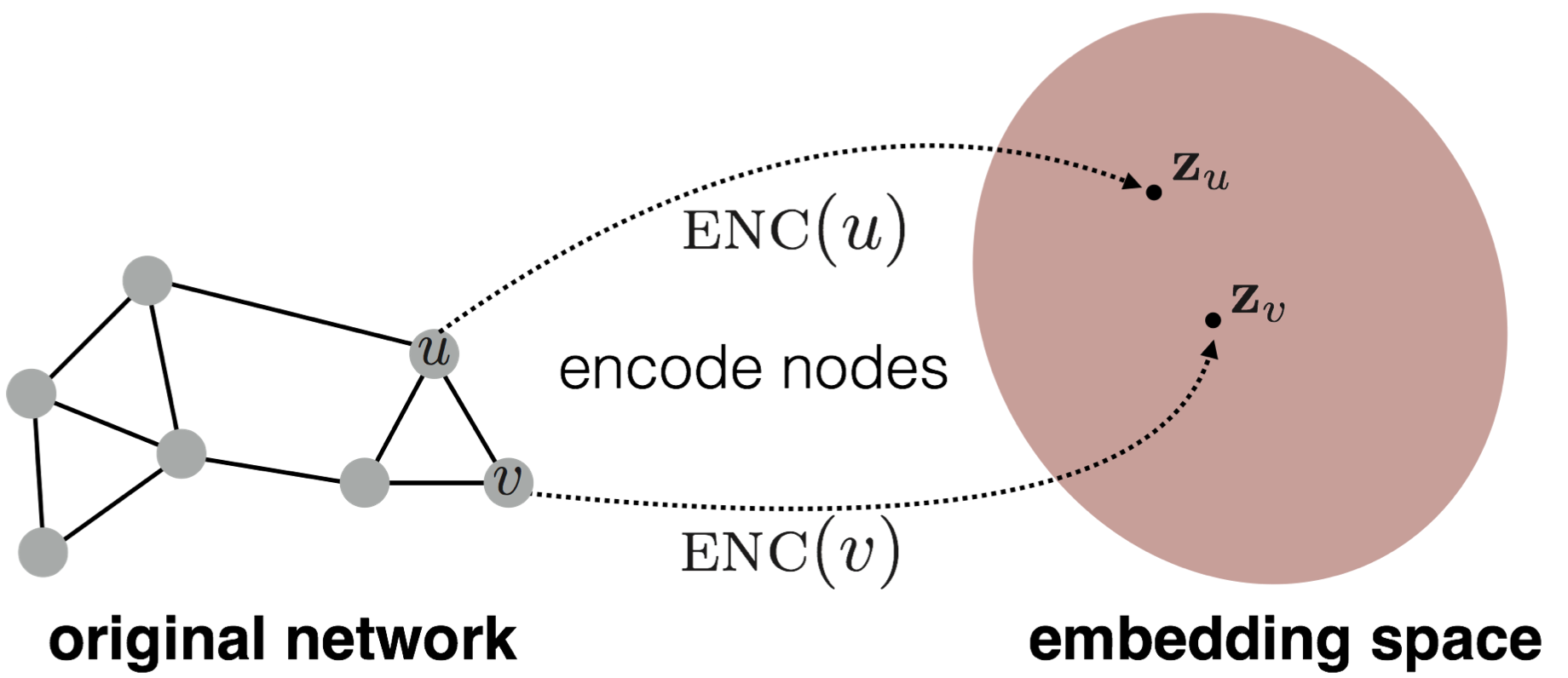 对节点进行表征后,我们就可以进行一系列的下游工作,如节点分类;边预测等下游任务。
对节点进行表征后,我们就可以进行一系列的下游工作,如节点分类;边预测等下游任务。
当然也有部分任务做 边表征/图表征,在此暂不作讨论。
GNN
A Gentle Introduction to Graph Neural Networks
节点向量初始化方式
完全随机初始化
和 BERT 的方法有点像,使用随机初始化的词嵌入,后续在训练过程中不断优化
固有特征初始化
直接使用节点的原始特征(如用户资料、分子属性等)
结构特征初始化
- 度信息(度中心性、局部聚类系数等)
- 拉普拉斯特征向量
- PageRank值
- 图核方法提取的特征
图嵌入方法生成的初始特征:
- DeepWalk、node2vec预训练的嵌入
- LINE、SDNE等方法生成的嵌入
- struc2vec等结构保持嵌入
边处理方式
基于边类型的特征表示(类型级别)
- 基于边类型的特征表示(类型级别):
- 每种类型的边共享相同的特征/参数
- 常见于知识图谱和异构图中的关系表示
- 代表模型:RGCN、HetGNN、GATNE
- 优势:参数量少,泛化性好,适合关系种类有限的图
针对每条具体边的特征(少见)
混合方式(常见):
- 同时考虑边类型和边特有属性
- 例如:[关系类型嵌入; 边属性向量]
- 代表模型:CompGCN、EdgeConv
- 优势:兼顾类型信息和实例特征
具体的 图神经网络
由于老师在上课时已经介绍了 GCN 和 GraphSage 这两种方法,在此就不进行重复的介绍了,接下来我们专注于实现。
Torch Gometric
Torch Geometric (简称 PyG) 是一个基于 PyTorch 的图神经网络(GNN)库,专门用于处理不规则数据结构。它提供了大量图神经网络层实现和常用基准数据集,使得图深度学习的研究和应用更加便捷。
Data模块
对于知识图谱(异构图),我们使用 HeteroData。这种模式和我们通常图像/时序等任务的输入很不一样。在图神经网络中,我们输入的是图,(通常的)输出为节点表征。
from torch_geometric.data import HeteroData
data = HeteroData()
# 添加节点特征 (假设 drug 有 128维特征, disease 有 64维)
data['drug'].x = torch.randn(num_drug_nodes, 128)
data['disease'].x = torch.randn(num_disease_nodes, 64)
# 添加边连接信息
# 假设有 E 条 'drug' -> 'treats' -> 'disease' 的边
drug_indices = torch.randint(0, num_drug_nodes, (E,))
disease_indices = torch.randint(0, num_disease_nodes, (E,))
data['drug', 'treats', 'disease'].edge_index = torch.stack([drug_indices, disease_indices], dim=0)
print(data)
# Output:
# HeteroData(
# drug={ x=[num_drug_nodes, 128] },
# disease={ x=[num_disease_nodes, 64] },
# (drug, treats, disease)={ edge_index=[2, E] }
# )在这个数据中,通过 .x 这种方式添加节点,通过 edge_indexs 添加边。边由三元组组成,
超大规模图处理技巧
在生物医学知识图谱等异构图中,将整个图加载到内存中在今天的技术条件下,有时是可行的。将采样后的知识图谱全部加载到 GPU 中进行处理,有时就省去了重复去采样子图的时间,减少采子图可能造成的少量偏差。
但有时面对过大规模的图,我们仍然需要采取采样子图的策略。通常,我们会采样本批次内所有出现的节点n step之内的邻居节点,这里邻居节点的采样step数量由模型层数决定。通常是 3-4。
在传播的过程中,节点会不断聚合周围的节点信息,通常来说,我们的HGT一般走四层左右就可以了。实际上,四个step远的距离已经很恐怖了,在较为稠密的生物医学知识图谱中,平均一个节点的周边节点可能有20个,
十六万个节点。这么多节点,足以表征一个节点周围的拓扑结构,具有足够的语义信息
模型架构示例
(AI Generated)
class HGT(torch.nn.Module):
"""The Heterogeneous Graph Sampler from the `"Heterogeneous Graph
Transformer" <https://arxiv.org/abs/2003.01332>`_ paper.
This loader allows for mini-batch training of GNNs on large-scale graphs
where full-batch training is not feasible.
Args:
data (Any): A :class:`~torch_geometric.data.Data`,
:class:`~torch_geometric.data.HeteroData`, or
(:class:`~torch_geometric.data.FeatureStore`,
:class:`~torch_geometric.data.GraphStore`) data object.
num_samples (List[int] or Dict[str, List[int]]): The number of nodes to
sample in each iteration and for each node type.
If given as a list, will sample the same amount of nodes for each
node type.
input_nodes (str or Tuple[str, torch.Tensor]): The indices of nodes for
which neighbors are sampled to create mini-batches.
Needs to be passed as a tuple that holds the node type and
corresponding node indices.
Node indices need to be either given as a :obj:`torch.LongTensor`
or :obj:`torch.BoolTensor`.
If node indices are set to :obj:`None`, all nodes of this specific
type will be considered.
"""
def __init__(self, data,hidden_channels, out_channels, num_heads, num_layers):
super().__init__()
self.lin_dict = torch.nn.ModuleDict()
for node_type in data.node_types:
self.lin_dict[node_type] = Linear(-1, hidden_channels)
self.convs = torch.nn.ModuleList()
for _ in range(num_layers):
conv = HGTConv(hidden_channels, hidden_channels, data.metadata(),
num_heads)
self.convs.append(conv)
self.lin = Linear(hidden_channels, out_channels)
def forward(self, x_dict, edge_index_dict):
for node_type, x in x_dict.items():
x_dict[node_type] = self.lin_dict[node_type](x.float()).relu_()
for conv in self.convs:
x_dict = conv(x_dict, edge_index_dict)
# output node representation
for node_type in x_dict.keys():
x_dict[node_type]=self.lin(x_dict[node_type])
return x_dict好的,我们来详细讲解一下 HGT 这个模型。
模型目的
HGT (Heterogeneous Graph Transformer) 模型是专门为 异构图(Heterogeneous Graphs) 设计的一种图神经网络。异构图是指包含 不同类型的节点 和 不同类型的边 的图。例如,在生物信息学中,一个图可能包含“基因”节点、“蛋白质”节点和“疾病”节点,以及它们之间不同类型的关系(如“基因编码蛋白质”、“蛋白质与蛋白质相互作用”、“基因与疾病相关”等)。
HGT 模型的主要目的是学习图中 每种类型节点的有效表示(embeddings)。这些表示(或称为嵌入、特征向量)能够捕捉节点自身的特征以及它们在复杂图结构中的关系信息。学习到的节点表示可以用于各种下游任务,比如节点分类、链接预测(判断两个节点间是否存在关系)或图分类。
初始化 (__init__)
def __init__(self, data,hidden_channels, out_channels, num_heads, num_layers):
super().__init__() # 调用父类初始化
# 1. 输入特征线性映射层 (字典)
self.lin_dict = torch.nn.ModuleDict()
# 遍历数据中所有的节点类型
for node_type in data.node_types:
# 为每种节点类型创建一个线性层
# Linear(-1, hidden_channels) 表示输入维度自动推断,输出维度为 hidden_channels
self.lin_dict[node_type] = Linear(-1, hidden_channels)
# 2. HGT 卷积层列表
self.convs = torch.nn.ModuleList()
# 根据指定的层数 num_layers 创建 HGT 卷积层
for _ in range(num_layers):
# 创建一个 HGTConv 层
# 输入和输出通道数都是 hidden_channels
# data.metadata() 提供了图的元信息 (节点类型、边类型)
# num_heads 是 Transformer 中的多头注意力机制的头数
conv = HGTConv(hidden_channels, hidden_channels, data.metadata(),
num_heads)
self.convs.append(conv) # 将创建的卷积层添加到列表中
# 3. 输出线性映射层
# 创建一个最终的线性层,将 HGTConv 输出的 hidden_channels 维度映射到指定的 out_channels 维度
self.lin = Linear(hidden_channels, out_channels)__init__(self, data, hidden_channels, out_channels, num_heads, num_layers): 模型的构造函数。data: 输入的异构图数据对象(通常是torch_geometric.data.HeteroData类型)。这个对象包含了图的结构信息(节点、边、类型)和节点的初始特征(如果有的话)。HGT需要从data中获取节点类型 (data.node_types) 和图的元数据 (data.metadata())。hidden_channels: 模型内部隐藏层的维度(通道数)。这是一个超参数,决定了节点表示的维度大小。out_channels: 模型最终输出的节点表示的维度。num_heads:HGTConv中多头注意力机制的头数。多头注意力允许模型同时关注来自邻居节点的不同方面的信息。num_layers:HGTConv卷积层的数量。层数越多,模型能聚合到距离更远的邻居信息。
self.lin_dict = torch.nn.ModuleDict(): 创建一个模块字典 (ModuleDict)。因为不同类型的节点可能有不同维度或性质的初始特征,所以需要为 每种节点类型 单独创建一个线性层 (torch.nn.Linear)。这个线性层的作用是将各种输入特征映射到统一的hidden_channels维度,方便后续卷积层处理。Linear(-1, hidden_channels)中的-1表示输入维度会根据第一次传入的数据自动推断。self.convs = torch.nn.ModuleList(): 创建一个模块列表 (ModuleList) 来存储HGTConv卷积层。模型会堆叠多个 (num_layers个)HGTConv层。HGTConv(...): 这是HGT模型的核心卷积层。它接收当前节点的表示、邻居节点的表示以及它们之间的边类型,利用基于 Transformer 的注意力机制来聚合邻居信息,并更新中心节点的表示。data.metadata()告诉HGTConv层图中存在哪些节点类型和边类型,以便它可以为不同类型的关系学习不同的转换权重。self.lin = Linear(hidden_channels, out_channels): 创建一个最终的线性层。在经过所有HGTConv层的处理后,节点的表示维度是hidden_channels。这个最终的线性层将这些表示映射到用户指定的out_channels维度,得到模型最终输出的节点表示。
前向传播 (forward)
def forward(self, x_dict, edge_index_dict):
# 1. 应用初始线性层和激活函数
# 遍历输入的节点特征字典 x_dict
for node_type, x in x_dict.items():
# 对每种节点类型的特征 x 应用对应的初始线性层 self.lin_dict[node_type]
# x.float() 确保输入是浮点数类型
# .relu_() 应用 ReLU 激活函数 (inplace 版本,直接修改张量)
x_dict[node_type] = self.lin_dict[node_type](x.float()).relu_()
# 2. 应用 HGT 卷积层
# 依次通过 ModuleList 中的每个 HGTConv 层
for conv in self.convs:
# HGTConv 层接收当前的节点表示字典 x_dict 和边索引字典 edge_index_dict
# 并返回更新后的节点表示字典
x_dict = conv(x_dict, edge_index_dict)
# 3. 应用最终线性层 (输出节点表示)
# 遍历经过 HGTConv 处理后的节点表示字典
for node_type in x_dict.keys():
# 对每种节点类型的表示应用最终的线性层 self.lin
x_dict[node_type] = self.lin(x_dict[node_type])
# 4. 返回结果
# 返回包含所有节点类型最终表示的字典
return x_dictforward(self, x_dict, edge_index_dict): 定义了模型如何处理输入数据以产生输出。- 输入:
x_dict: 一个字典。键 (key) 是节点类型(字符串),值 (value) 是对应节点类型的特征矩阵(torch.Tensor),形状通常是[num_nodes, input_feature_dim]。这是节点的初始输入特征。edge_index_dict: 一个字典。键 (key) 是一个描述边类型的元组(source_node_type, relation_type, target_node_type),值 (value) 是表示这种类型边的连接关系的edge_index张量(torch.Tensor),形状通常是[2, num_edges_of_type]。edge_index[0]是源节点索引列表,edge_index[1]是目标节点索引列表。这个字典描述了图的连接结构。
- 处理流程:
- 初始映射: 首先,对
x_dict中的每种节点类型的特征,应用其在self.lin_dict中对应的线性层进行变换,并将维度统一到hidden_channels。然后应用 ReLU 激活函数增加非线性。 - HGT 卷积: 接着,将经过初始映射的
x_dict和edge_index_dict传入HGTConv层。模型会迭代地执行这个过程num_layers次。在每一层,HGTConv会根据edge_index_dict描述的图结构,利用注意力机制聚合来自不同类型邻居节点的信息,更新x_dict中所有节点的表示。 - 最终映射: 经过所有
HGTConv层后,x_dict中的节点表示维度是hidden_channels。最后,对x_dict中每种节点类型的表示应用最终的线性层self.lin,将其维度映射到out_channels。
- 初始映射: 首先,对
- 输出:
x_dict: 一个字典。结构与输入的x_dict类似,但值是模型最终学习到的节点表示。键是节点类型(字符串),值是对应节点类型的最终表示矩阵(torch.Tensor),形状是[num_nodes, out_channels]。
- 输入:
num_nodes 就是本批次的node。
HGT 模型接收一个异构图的节点初始特征 (x_dict) 和图结构 (edge_index_dict) 作为输入。通过一系列针对不同节点类型定制的初始线性变换、多层 HGTConv 卷积(利用注意力机制聚合邻居信息)以及最终的线性变换,输出图中每种节点类型的学习到的、维度为 out_channels 的表示 (x_dict)。这些输出表示旨在捕捉节点的特征和图的结构信息。
MegaBatch?
可以注意到,我们这里输出的是一个高维的向量,而不是一个标签之类的。这实际上是一种优化技巧。假设我们下游任务,是预测边,那么我们每个节点只需要进行一次嵌入,然后后续在边预测的过程中再进行反向传播。中间注意不要让计算图断开即可,即保持 tensor 矩阵。
例如,我每一个Epoch,Embedding 了 300 个节点,而链接有 5000 条。那么,我就可以在预测出所有的Embedding,再通过链接预测算出 Loss,一次性反向传播一个 MegaBatch(超大批次),进行权重更新。
这是一个可选的策略,能够提高计算效率,但是对显存要求较高。最好提前规划、计算好显存消耗再实施,否则很容易炸。
如果不使用这种策略,我们还是每个batch输入多对节点对,即使有重复的也没办法,我们只能进行一些重复的计算,来节约显存。
对上节课的补充:MPNN 结构
在 MPNN 这篇工作之前整个图神经网络的研究缺少一个统一的范式和框架。MPNN 作为一个框架,很好地将整个 GNN 领域做了一个标准化。它通过三个函数描述几乎所有静态图神经网络的流程:
- 消息生成(Message Function)
- 消息聚合(Aggregation)
- 状态更新(Update Function) 下面,我们用两个图神经网络的例子,来描述 MPNN 下的图神经网络结构。
1. GCN(Graph Convolutional Networks)
论文:Kipf & Welling, 2016 (Semi-Supervised Classification with Graph Convolutional Networks, ICLR)
核心思想:将传统卷积推广到图结构数据,通过邻域节点的加权聚合更新节点表示。
MPNN 框架下的 GCN
(1) 消息函数(Message Function)
- 定义:
对邻居节点 的特征进行归一化线性变换:
:可学习的权重矩阵。
:基于节点度的归一化(GCN 的对称归一化技巧)。
(2) 聚合函数(Aggregation)
- 操作:对邻居消息求和(含自环):
- 自环(节点自身)也被包含在聚合中。
(3) 更新函数(Update Function)
- 定义:对聚合结果应用非线性激活(如 ReLU):
:激活函数,通常为 ReLU。
2. GG-NN(Gated Graph Neural Networks)
论文:Li et al., 2015 (Gated Graph Sequence Neural Networks, arXiv)
核心思想:引入门控机制(GRU)控制信息传播,适用于序列化的图任务(如程序分析)。
MPNN 框架下的 GG-NN
(1) 消息函数(Message Function)
- 定义:对邻居节点的状态进行线性变换(边类型相关):
:与边类型 相关的可学习矩阵(不同边类型有不同的权重)。
(2) 聚合函数(Aggregation)
- 操作:直接求和所有邻居消息:
(3) 更新函数(Update Function)
- 定义:使用 GRU 结合历史状态和当前消息:
- GRU 的输入:上一时刻的节点状态 和聚合消息 。
3. GRU(Gated Recurrent Unit)详解
GRU 是循环神经网络(RNN)的一种变体,由 Cho 等人于 2014 年提出,用于解决传统 RNN 的梯度消失问题。
GRU 的核心结构
GRU 通过两个门控机制(重置门 和更新门 )控制信息流:
:Sigmoid 函数,输出值在 [0,1] 之间,表示门的开放程度。
:逐元素乘法,重置门 控制历史状态的“遗忘”程度。
更新门 平衡旧状态和新候选状态的比例。
更复杂的架构:GAT
GAT(Graph Attention Network)由 Velickovic 等人于 2018 年提出(Graph Attention Networks, ICLR 2018),其核心创新是用注意力权重动态计算邻居节点的重要性,而非像 GCN 那样依赖固定的归一化权重。
(1) 消息函数(Message Function)
在 GAT 中,消息函数不仅考虑邻居节点的特征,还通过注意力机制学习权重:
:可学习的线性变换矩阵(与 GCN 类似)。
:注意力权重,表示节点 对节点 的重要性,计算方式为:
:可学习的注意力向量。
:向量拼接操作。
softmax_u:
对节点 的所有邻居 归一化,使得
。
(2) 聚合函数(Aggregation)
GAT 的聚合是对加权消息求和:
(3) 更新函数(Update Function)
GAT 的更新函数通常是一个简单的非线性变换(类似 GCN):
:如 ELU 或 LeakyReLU。
总结
图神经网络的构建是高度可定制化的。我们无法遍历所有的组合,但我认为,深度学习的一个原则就是:合理地整合一切你能够整合进去的信息,并使用合适的模型架构进行处理。比如,我们的节点如果具有各种信息,如类型,我们可以给类型一个初始嵌入;如果有其他信息,如更多基因表达等的信息,我们可以考虑,在输入GNN的时候进行融合,还是在中期,即输出 Embedding 之后进行融合等。
尤其在GNN 中,没有标准的范式:是否要对边进行表征,还是只对节点进行卷积?是否进行预训练?下游如何微调?总而言之,GNN 提供了一个强大的框架,但具体如何实例化这个框架,如何表示节点和边,如何以及何时融合外部信息,都需要根据具体问题进行仔细的设计和权衡。这种高度的可定制化既是 GNN 的魅力所在,也是其应用的挑战之一。