从代码入手 光速入门深度学习
常规深度学习流程图
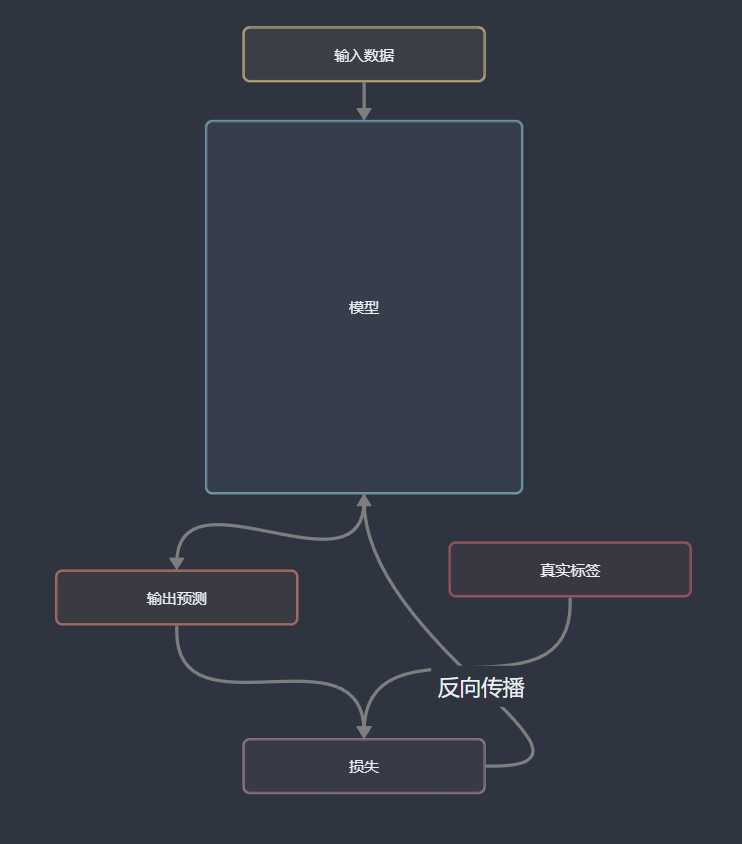
常规的、多数情况下的深度学习的流程框架可以被抽象为上方这个流程图。
首先,我们准备输入数据。输入数据一般被处理为成向量,然后输入模型,输出预测。预测的结果与真实标签通过损失函数计算得出损失,最后损失反向传播,更新模型参数。
下面我们从一个示例代码开始,快速带同学们入门深度学习。
import
import config
import random, shutil, os
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Dataset
from sklearn.metrics import classification_report, confusion_matrix
import numpy as np
import pandas as pd
from tqdm.auto import tqdm
import os这是一个示例代码的import部分。这些包可能有些同学不认识我们大概来过一下:
- matplotlib 是可视化的库,具体怎么用我们后面可能会提到
- torch 是深度学习的框架。大家可能已经听说过了
- torchvision 是针对于计算机视觉这一个task的库。我们后面会介绍
- numpy pandas应该不用我介绍了,应该没人没用过吧
- sklearn是机器学习库。需要注意的是,下载时需要使用
pip install scikit-learn,直接使用sklearn下不下来。
设置超参数
接下来我们通常会设置超参数。超参数的设置方式也有比较多种,第一种是使用大写的变量,如:
SEED = 42
LR = 1e-4
BATCH_SIZE = 32
self.EPOCHS = 10
self.DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.MODEL_SAVE_PATH = 'best_model.pth'
self.DATA_DIR = './data'也有人会喜欢这么写:
class Config:
def __init__(self):
self.SEED = 42
self.LR = 1e-4
self.BATCH_SIZE = 32
self.EPOCHS = 10
self.DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.MODEL_SAVE_PATH = 'best_model.pth'
self.DATA_DIR = './data' # 数据集路径
config = Config()一般使用 argparse 这种方式更加专业:
import argparse
# 设置argparse参数解析
parser = argparse.ArgumentParser(description='深度学习训练脚本')
parser.add_argument('--seed', type=int, default=42, help='随机种子')
parser.add_argument('--lr', type=float, default=1e-4, help='学习率')
parser.add_argument('--batch_size', type=int, default=32, help='批量大小')
parser.add_argument('--epochs', type=int, default=10, help='训练轮次')
parser.add_argument('--device', type=str, default='auto', help='设备选择(auto/cuda/cpu)')
parser.add_argument('--model_save_path', type=str, default='best_model.pth', help='模型保存路径')
parser.add_argument('--data_dir', type=str, default='./data', help='数据目录')
args = parser.parse_args()
if args.device == 'auto':
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
else:
DEVICE = torch.device(args.device)
# 调用时使用类似:
torch.manual_seed(args.seed)需要用bash脚本使用和控制版本等。
也有一些方法,写外部的config文件等。管理方法很多,使用你习惯、用得顺手的即可。
设置随机种子
一般来说,在import的下一个步骤,我们会设置随机种子保证结果可复现。例如:
# 设置随机种子确保结果可复现
def set_seed(seed=42):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
set_seed(args.seed)数据预处理
在数据预处理部分,我们需要将数据清洗、整理好(如果需要),分割训练集、验证集、测试集,并打包为dataset类。
训练集、验证集、测试集分割
假设你拿到的是一个完整的数据集:
train_indices, test_indices = train_test_split(
indices,
test_size=0.2,
random_state=42,
stratify=full_dataset.targets.numpy()
)train_indices, val_indices = train_test_split(
train_indices,
test_size=0.25,
random_state=42,
stratify=[full_dataset.targets[i] for i in train_indices]
)可以选择使用索引分割的方式。索引分割对内存较为友好。当然,也可以直接加载所有数据分割数据(如果数据规模不大),但速度会变慢。你可以针对路径/索引等先进行分割。
初学者可能会经常分不清训练集、验证集和测试集的概念。这在机器学习中是极其重要的概念,最好不要搞混。
训练集(Train Set):
用于模型训练。它们会通过模型输入,输出预测标签,和真实标签计算损失,然后损失被反向传播。训练集是被模型拟合的对象。
验证集(Valid Set):
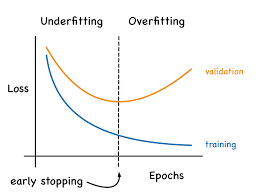
用于超参数调优、模型选择。通常来说,在训练的时候,我们会在每个epoch结束后,或者在多少个step结束后,使用验证集进行一轮验证。在这个过程中不会计算梯度,但会和真实标签计算一些指标,如准确率和Loss。通常来说,我们通过观察这个指标来确定模型训练的情况,比如其是否发生了过拟合(反映在指标上是训练Loss很小/准确率很高但验证集上Loss较高/准确率不高)。
一种常见的模型选择策略是选择在验证集上分数最高的模型。
我们还可以基于验证集的分数/Loss来确定早停策略。比如,当验证集的 Loss 在5个 epoch 上没有改善的时候,我们就会提前停止训练节省时间。
测试集(Test Set):
测试集是测试模型最终能力的“考试”。比如说,我们会拿着验证集上表现最好的模型在测试集上面跑。测试集应当真实地考验模型的泛化能力,理论上,你不可以照着测试集的指标去调参等。这种操作叫做“人工过拟合测试集”,很可能导致模型能力被错误地反映。
最好情况下,在数据充足的情境下,一个测试集最好只被使用一次。当然,在大部分情况下,这种方式不太可行。太奢侈了(
交叉验证(Cross Validation)
当数据量有限时,简单的训练/验证集分割可能导致评估结果不稳定。此时可采用交叉验证:将训练数据划分为K个子集(称为”折”),每次用K-1折训练,剩余1折验证,循环K次后取平均结果:
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_idx, val_idx in kf.split(dataset):
# 每个fold的训练和验证逻辑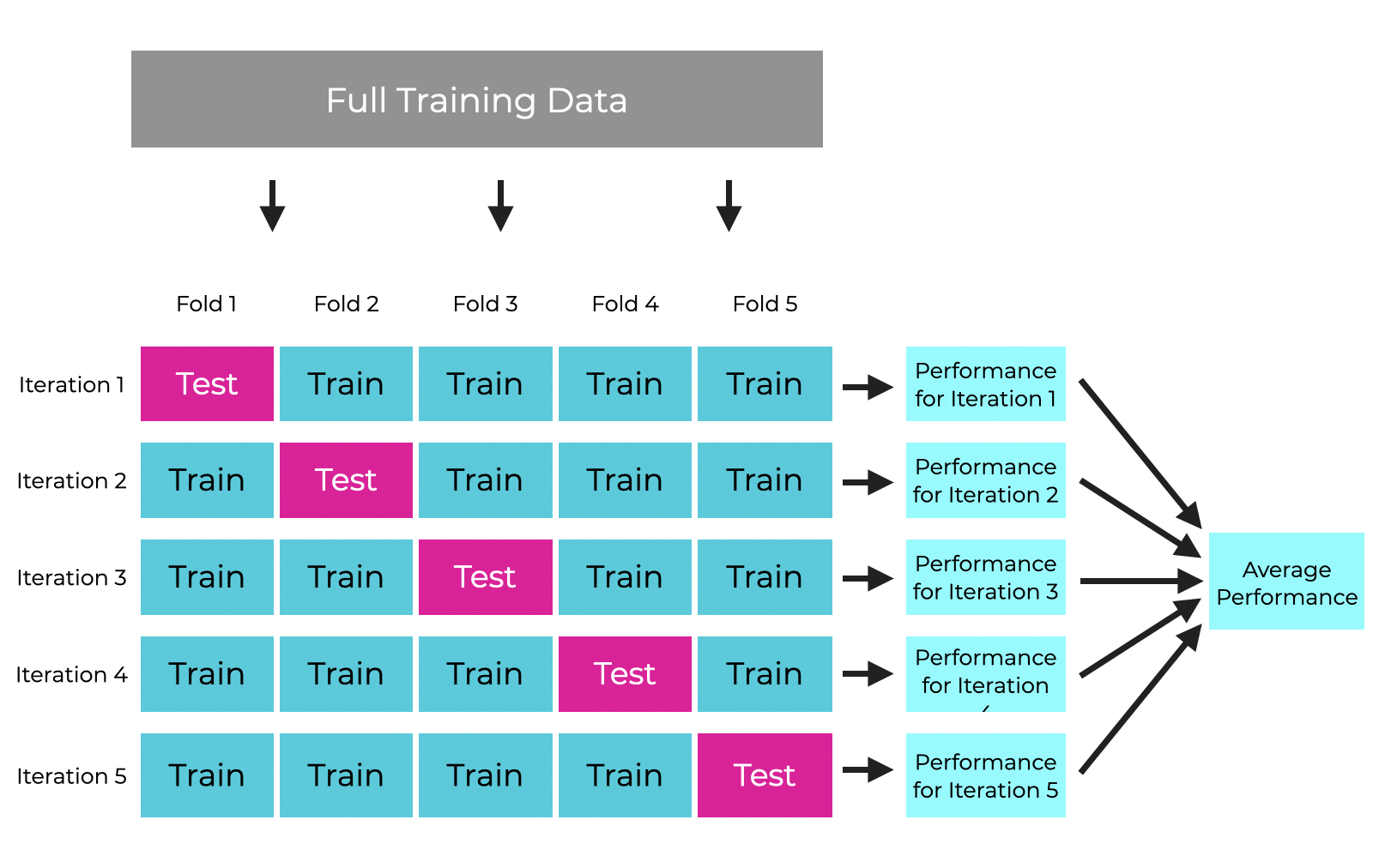 交叉验证主要用于:
交叉验证主要用于:
- 模型性能评估(比单次分割更可靠)
- 超参数调优(结合网格搜索/随机搜索)
- 小样本数据下的模型选择
注意:交叉验证仅应用于训练阶段,最终模型仍需在独立的测试集上进行最终评估。相当于分割的时候,我们先将测试集分割出去,然后将训练集和验证集按照Cross Validation的方式进行划分。
缺点:训练时间 * k ,耗时很长。
PyTorch Dataset与DataLoader构建
Dataset
class CustomDataset(Dataset):
def __init__(self, data, targets, transform=None):
self.data = data
self.targets = targets
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
sample = self.data[idx]
label = self.targets[idx]
if self.transform:
sample = self.transform(sample)
return sample, label你需要根据自己的数据格式,自行实现 Dataset 这个 class。大部分情况下,这个东西你都需要自己根据数据格式去自定义。
下面详细讲讲Class里面的每一个方法
Init 方法
def __init__(self, data_dir, transform=None):
"""
初始化数据集
:param data_dir: 数据存储目录
:param transform: 数据预处理/增强操作
"""
self.data_dir = data_dir
self.transform = transform
# 加载数据列表(示例)
self.samples = self._load_data()首先是Init 方法。在Init 方法中,我们需要定义 Class 中的一些基本对象。比如,我们可以在这里定义你数据存放的路径,当然,部分任务比如图像任务中可能需要输入一个 transform 也就是数据增强或者变换的方法。
在这里,不建议真正地加载所有数据。在很多任务中,数据很大,一次性加载会占用内存,并且会导致项目启动很慢。
len 方法
接着,是 len 方法。需要正确地返回样本的长度。如果你使用 Dataset,这个方法必须实现
def __len__(self):
"""返回数据集总样本数"""
return len(self.samples)在一些特殊情况下,我们的数据可能是流式的,或不方便获取长度的。此时在函数定义时,我们就不应使用Dataset,而应该使用 IterableDataset
例如:
from torch.utils.data import IterableDataset
class StreamDataset(IterableDataset):
def __init__(self, data_generator):
self.data_generator = data_generator # 数据生成器/迭代器
def __iter__(self):
return self.data_generator()getitem
def __getitem__(self, idx):
img_name = self.image_files[idx]
img_path = os.path.join(self.root_dir, img_name)
image = Image.open(img_path).convert('RGB')
label = self.class_to_idx[img_name.split('_')[0]]
if self.transform:
image = self.transform(image)
return image, label在这个方法中,你需要实现实际加载数据的方法。它应当加载你数据中的一个样本。
实例化dataset
train_dataset = CustomDataset(
filepaths=[all_filepaths[i] for i in train_indices],
labels=[all_labels[i] for i in train_indices],
transform=train_transform
)
val_dataset = CustomDataset(
filepaths=[all_filepaths[i] for i in val_indices],
labels=[all_labels[i] for i in val_indices],
transform=val_transform
)
test_dataset = CustomDataset(
filepaths=[all_filepaths[i] for i in test_indices],
labels=[all_labels[i] for i in test_indices],
transform=test_transform
)在图像任务中,通常在 train_transform 中我们会进行数据增强,但是在 val 和 test中,我们在 transform中可能只做标准化。
DataLoader 方法
from torch.utils.data import DataLoadertrain_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)DataLoader 能够将dataset 进行打包。一般来说,我们会在数据上加上一个 batchsize 的维度。在DataLoader方法中,它还能够承担 shuffle 洗混数据的目的。
(疑难杂症:如果你写的代码中在 dataset 中使用 num_workers 了,并且在jupyter notebook 中使用,你可能会发现训练时进度条不会动。请删除 num_workers 这个参数,或不要使用jupyter notebook)
模型构建
在PyTorch中,我们通常通过继承nn.Module类来构建模型:
class SimpleCNN(nn.Module):
def __init__(self, num_classes=10):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 8 * 8, 512)
self.fc2 = nn.Linear(512, num_classes)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 8 * 8) # 展平处理
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return xexample 模型关键组件说明:
- 卷积层 (Conv2d):
- 提取图像局部特征
- 参数:输入通道数、输出通道数、卷积核大小、padding等
- 池化层 (MaxPool2d):
- 降低空间维度(下采样)
- 增强平移不变性
- 全连接层 (Linear):
- 将提取的特征映射到类别空间
- 输入维度需要根据前层输出计算
- Dropout层 :
- 随机失活神经元防止过拟合
- 训练时生效,测试时自动关闭
- 激活函数 (ReLU):
- 引入非线性
- 解决梯度消失问题
其余技巧或写法
残差
def forward(self, x):
identity = x
x = F.relu(self.bn1(self.conv1(x)))
x = self.bn2(self.conv2(x))
x += identity # 残差连接
return F.relu(x)批量归一化
class SimpleCNN(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 32, 3, padding=1),
nn.BatchNorm2d(32), # 添加BN层
nn.ReLU()
)配置化模型构建
实验/参数调优时使用
def create_cnn(config):
layers = []
in_channels = 3
for out_channels in config['channels']:
layers += [
nn.Conv2d(in_channels, out_channels, **config['conv_params']),
nn.ReLU(),
nn.MaxPool2d(**config['pool_params'])
]
in_channels = out_channels
return nn.Sequential(*layers)
config = {
'channels': [32, 64],
'conv_params': {'kernel_size': 3, 'padding': 1},
'pool_params': {'kernel_size': 2, 'stride': 2}
}自定义层实现
class AttentionLayer(nn.Module):
def __init__(self, channels):
super().__init__()
self.fc = nn.Linear(channels, 1)
def forward(self, x):
weights = F.softmax(self.fc(x.view(x.size(0), x.size(1), -1)), dim=2)
return (x.view(x.size(0), x.size(1), -1) * weights).sum(dim=2)模型实例化
model = SimpleCNN(num_classes=10).to(DEVICE)DEVICE 由之前的参数定义,可以为 cpu/cuda。
如果在多卡环境,可以指定显卡ID,如 DEVICE = "cuda:0"
自动多卡并行:
model = DataParallel(model)请了解清楚后使用,否则可能会导致反效果。
损失函数
损失函数有部分常用的,可以直接调用。例如:
criterion = nn.CrossEntropyLoss()如果有特殊需求,你也可以自行定义。示例为在类别不平衡情况下使用的 FocalLoss
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2.0):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
def forward(self, inputs, targets):
# 计算交叉熵损失
BCE_loss = F.cross_entropy(inputs, targets, reduction='none')
# 计算概率
pt = torch.exp(-BCE_loss)
# Focal Loss公式:FL = α(1-pt)^γ * CE
loss = self.alpha * (1-pt)**self.gamma * BCE_loss
return loss.mean()
请使用torch张量操作,确保所有操作在计算图中可导。
优化器
1. 随机梯度下降(SGD with Momentum)
原理
SGD的核心是通过负梯度方向更新参数,但引入动量(Momentum)加速收敛:
- 参数更新公式:
- v_t:累积的动量(历史梯度的指数加权平均)
- \beta(如0.9):动量系数,控制历史梯度的贡献
- \eta:学习率
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)2. Adam(Adaptive Moment Estimation)
原理
Adam结合了动量(一阶矩)和自适应学习率(二阶矩):
作用
- 自适应学习率:参数更新步长根据梯度历史动态调整(梯度大的方向步长小,反之亦然)。
- 快速收敛:一阶矩加速方向调整,二阶矩自适应步长。
问题
- 泛化能力:可能收敛到尖锐极小值,导致测试性能下降。
- 偏差校正:初始阶段 偏小,需校正()。
3. AdamW
原理
AdamW改进了Adam的权重衰减(L2正则化)方式,解耦权重衰减与梯度更新:
作用
- 解耦正则化:权重衰减直接作用于参数,而非梯度(Adam的L2正则化会与自适应学习率耦合)。
- 提升泛化:尤其适合Transformer等复杂模型,减少过拟合。
问题
- 学习率预热:初始阶段需配合预热策略(warmup),避免梯度不稳定。
对比:
| 优化器 | 收敛速度 | 内存消耗 | 超参数敏感度 |
|---|---|---|---|
| SGD | 慢 | 低 | 高 |
| Adam | 快 | 高 | 低 |
| AdamW | 快 | 高 | 中 |
为什么 Adam 会消耗更多的显存?
- 状态变量存储 :
- Adam 维护两个状态变量:
- :梯度的一阶矩(均值)。
- :梯度的二阶矩(未中心化的方差)。
- AdamW 同样维护 mt 和 vt,但对权重衰减的处理方式不同,不增加额外状态变量。
- Adam 维护两个状态变量:
- 参数规模的影响 :
- 假设模型有 N 个参数,每个参数需要存储:
- 当前值(
param)。 - 梯度(
param.grad)。 - 一阶矩(
m)。 - 二阶矩(
v)。
- 当前值(
- 总计显存占用 :每个参数需要存储 4 个浮点数(SGD 只需存储
param和param.grad)。
- 假设模型有 N 个参数,每个参数需要存储:
学习率调度器
学习率调度器通过动态调整优化器的学习率,帮助模型在训练过程中更高效地收敛,避免陷入局部最优或震荡。
这也是个玄学东西,多种多样。 比较流行的一个:CosineAnnealingLR
CosineAnnealingLR
下图的这种叫Initial_Warmup_Cosine_Annealing_With_Weight_Decay
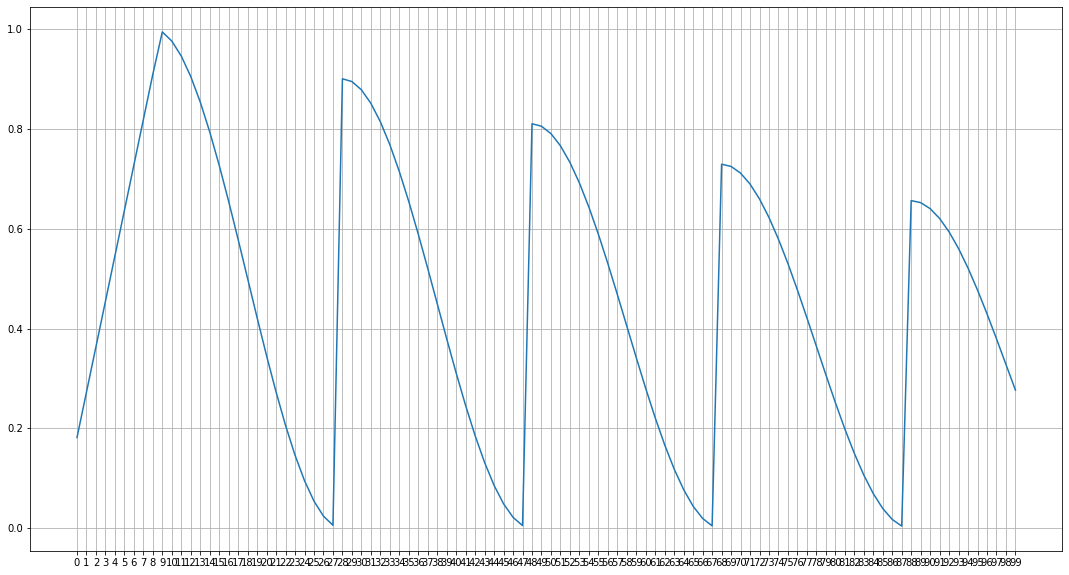
这里就随便介绍一种,种类太多了 大家感兴趣自己搜吧
示例代码(StepLR的):
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)调度器需要与 优化器绑定。 即: 优化器和模型绑定 调度器和优化器绑定
训练过程
其实写法也多种多样。这里放一种比较常见的的。
训练部分
def train(model, dataloader, criterion, optimizer, device):
model.train()
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in tqdm(dataloader, desc="Training"):
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计损失和准确率
running_loss += loss.item() * inputs.size(0)
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
epoch_loss = running_loss / len(dataloader.dataset)
epoch_acc = correct / total
return epoch_loss, epoch_acc将数据和模型放到同一个设备上
inputs, labels = inputs.to(device), labels.to(device) 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)反向传播
第一步需要清空调度器的梯度。pytorch的默认行为是让优化器的梯度累计。
optimizer.zero_grad()第二步是计算梯度,pytorch启动自动求导步骤
loss.backward()第三步是 optimizer.step() 使用根据上一步算出的梯度,更新模型参数
optimizer.step()第四步是更新学习率。它在train函数之外实现,或者在模型参数更新之后的任意位置更新就可以。如果在每个epoch之内调用,就是每个step更新一次;如果在每个epoch外更新,就是每个epoch更新一次。
scheduler.step()计算训练准确率等
# 统计损失和准确率
running_loss += loss.item() * inputs.size(0)
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
epoch_loss = running_loss / len(dataloader.dataset)
epoch_acc = correct / total
return epoch_loss, epoch_acc验证部分
验证部分可以让我们实时地在训练过程中知道模型性能,以方便进行参数调优等。 例如你发现训练准确率和验证准确率差距过大,那么很可能模型就发生了过拟合。
def validate(model, dataloader, criterion, device):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in tqdm(dataloader, desc="Validating"):
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item() * inputs.size(0)
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
epoch_loss = running_loss / len(dataloader.dataset)
epoch_acc = correct / total
return epoch_loss, epoch_acc在测试的部分,我们首先要开启 model.eval()
这告诉pytorch,在这个函数中下面的部分不需要计算梯度。
quiz: 假设我们使用了 Adam优化器,这里我们模型所需要使用的参数量是训练时候的多少分之一?
由于使用的内存减少了,在validation和test的时候,我们batch size也可以开大一些。
测试代码比较简单,只需要前向传播就可以了。
训练循环
# 初始化最佳模型参数
best_val_loss = float('inf')
patience = 5 # 早停耐心值
counter = 0
# 训练历史记录
history = {
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': []
}
for epoch in range(args.epochs):
print(f"\nEpoch {epoch+1}/{args.epochs}")
# 训练阶段
train_loss, train_acc = train(
model,
train_loader,
criterion,
optimizer,
DEVICE
)
# 验证阶段
val_loss, val_acc = validate(
model,
val_loader,
criterion,
DEVICE
)
# 记录训练历史
history['train_loss'].append(train_loss)
history['train_acc'].append(train_acc)
history['val_loss'].append(val_loss)
history['val_acc'].append(val_acc)
# 早停机制
if val_loss < best_val_loss:
best_val_loss = val_loss
counter = 0
torch.save(model.state_dict(), args.model_save_path)
print("Model saved.")
else:
counter += 1
if counter >= patience:
print("Early stopping triggered.")
break
# 打印当前状态
print(f"Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.4f}")
print(f"Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.4f}")这里设置了早停代码。
测试、验证和可视化
自己做吧!
记录保存
保存实验记录十分重要! python提供了多种保存记录的方式,比如内置的logger
这里不教具体实现了,但大家做实验的时候一定要详细地保存。你可以保存的东西:
- 训练参数
- 训练结果
- 模型的架构、实现
- 使用的数据集
- 实验时间
- …
最好详细地保存所有过程中的记录。如果机器上的空间允许,也最好多多保存模型。